Jan.ai Integration
Overview
Jan AI is an open-source alternative to ChatGPT that runs completely locally on your device. It provides a user-friendly interface for interacting with various language models while maintaining privacy and offline capability.
Key Features
- Local Processing: Run AI models entirely on your own hardware
- Multiple Model Support: Use various open-source LLMs
- User-Friendly Interface: Clean, intuitive chat experience
- Context Management: Save and organize conversations
- Document Processing: Upload and analyze documents locally
Use Cases
- Private communications without cloud-based monitoring
- Offline productivity and assistance
- Research and education in restricted environments
- Specialized domain applications with custom models
- Personal knowledge management and note-taking
Setup Instructions
- Install Jan AI:
- Visit the Jan AI website
- Download the installer for your operating system
- Run the installer and follow the setup process
- Launch Jan AI:
- Open the application after installation
- Complete the initial setup wizard
- Download Models:
-
Navigate to the settings
-
Under “Remote engine” section, choose OpenAI
-
Under “Advanced Settings” configure the relaxAI endpoint
-
Enter the following:
Chat Completion URL: https://api.relax.ai/v1/chat/completionsModel List URL: https://api.relax.ai/v1/models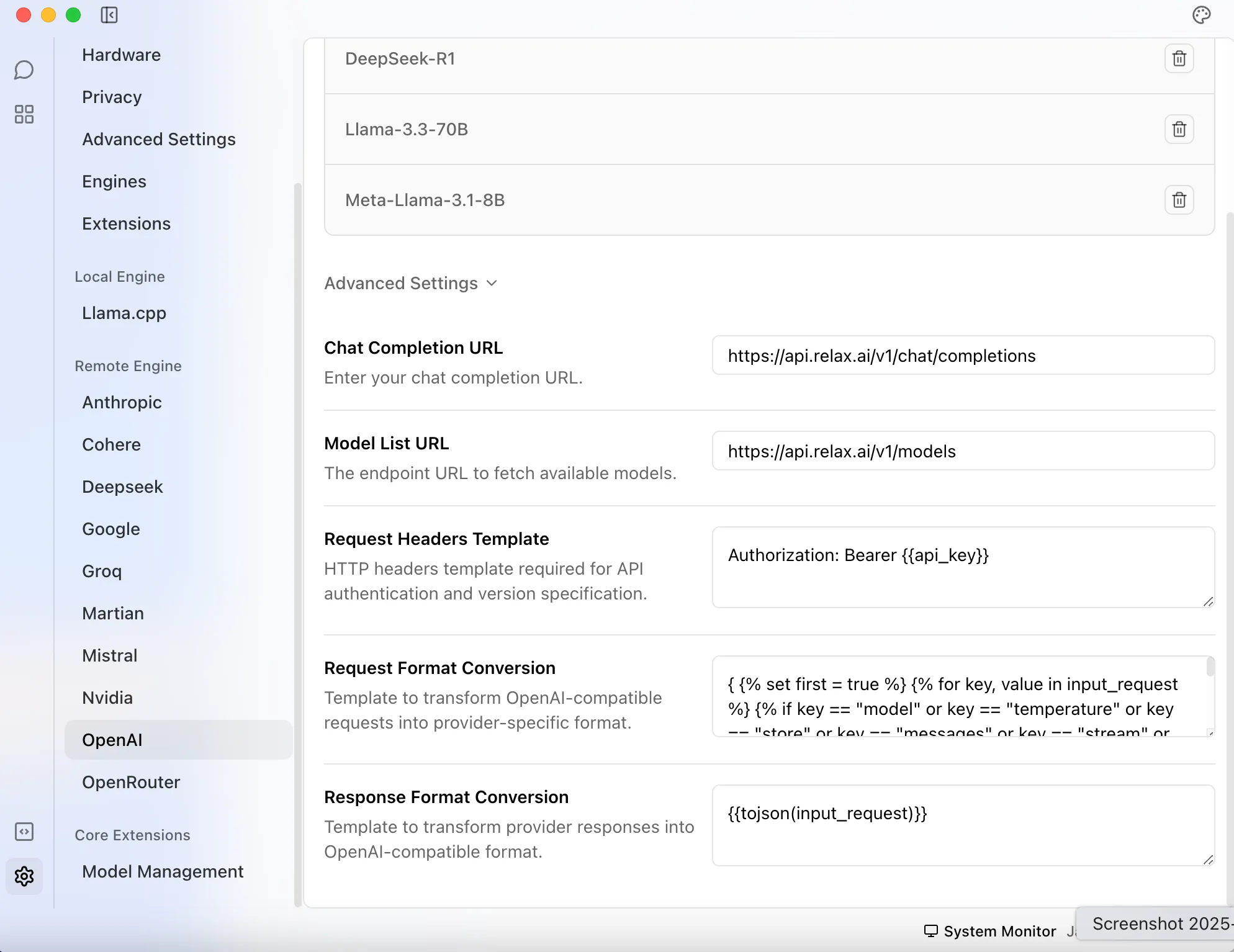
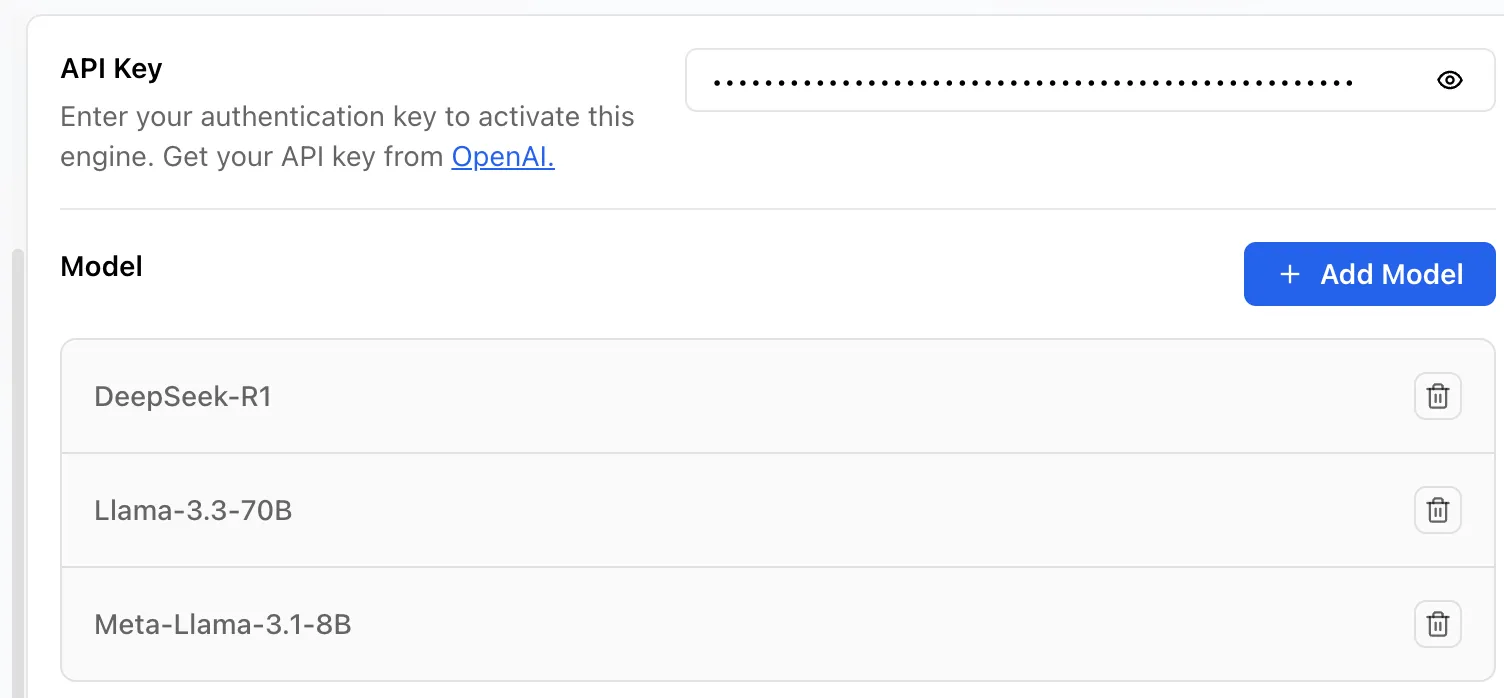
- Enter your API key on the top
- Click “Add Model” to download the models you want to use.
-
Configure API Server:
- If you want to route it through local API server, go to “Settings” → “Advanced”
- Enable “Local API Server”
- Note the API URL and port (typically http://localhost:1337)
-
Use API with External Applications:
- Connect to Jan AI using the OpenAI-compatible API
- Base URL:
http://localhost:1337/v1/ - API Key: Use any non-empty string as the API key
API Usage Examples
Python Example
import openai
# Configure the client to use Jan AIopenai.api_base = "http://localhost:1337/v1"openai.api_key = "jan-ai-local" # Can be any string
# Make a completion requestresponse = openai.ChatCompletion.create( model="local-model-name", # Use your downloaded model name messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Write a short poem about technology."} ], temperature=0.7, max_tokens=300)
print(response.choices[0].message['content'])Advanced Configuration
-
Model Parameters:
- Adjust inference settings for each model:
- Temperature: Control creativity and randomness
- Top P: Adjust nucleus sampling threshold
- Context Window: Set conversation history length
- Adjust inference settings for each model:
-
Memory Management:
- Configure RAM allocation for different models
- Set up disk cache for large context windows
- Optimize for your specific hardware configuration
-
Document Processing:
- Upload PDFs, text files, and other documents
- Configure document indexing and chunking settings
- Adjust retrieval parameters for question answering
Troubleshooting Tips
- If you experience slow performance, try using smaller models or reducing context length
- For GPU acceleration issues, ensure your drivers are up to date
- If the API server isn’t accessible, check that it’s enabled and the port isn’t blocked
- Verify model compatibility with your hardware specifications